Discussion and reports on my research activities.

Do you have original and sound research results concerning compute and storage clouds, distributed computing, crowdsourcing and human interaction with clouds, utility, green and autonomic computing, scientific computing or big data? (Or do you know people who surely have?)
UCC 2013, the premier conference on these topics with its six co-located workshops, welcomes academic and industrial submissions to advance the state of the art in models, techniques, software and systems. Please consult the Call for Papers and the complementary calls for Tutorials and Industry Track Papers as well as the individual workshop calls for formatting and submission details.
This will be the 6th UCC in a successful conference series. Previous events were held in Shanghai, China (Cloud 2009), Melbourne, Australia (Cloud 2010 & UCC 2011), Chennai, India (UCC 2010), and Chicago, USA (UCC 2012). UCC 2013 happens while cloud providers worldwide add new services and increase utility at a high pace and is therefore of high relevance for both academic and industrial research.
Choice is good for users, but when too much choice becomes a problem, smart helpers are needed to choose the right option. In the world of services, there are often functionally comparable or even equivalent offers with differences only in some aspects such as pricing or fine-print regulations. Especially when using services in an automated way, e.g. for storing data in the cloud underneath a desktop or web application, users could care less about which services they use as long as the functionality is available and selected preferences are honoured (e.g. not storing data outside of the country).
The mentioned smart helpers need a brain to become smart, and this brain needs to be filled with knowledge. A good way to represent this knowledge is through ontologies. Today marks the launch of the consolidated WSMO4IoS ontology concept collection which contains this knowledge specially for contemporary web services and cloud providers. While still in its infancy, additions will happen quickly over the next weeks.
One thing which bugged me when working with ontologies was the lack of a decent editor. There are big Java behemoths available, which certainly can do magic for each angle and corner allowed by the ontology language specifications, but having a small tool available would be a nice thing to have. And voilà, the idea for the wsmo4ios-editor was born. It's written in PyQt and currently, while still far from being functional, 8.3 kB in size (plus some WSML-to-Python code which could easily be generated on the fly). The two screenshots show the initial selection of a domain for which a service description should be created, and then the editor view with dynamically loaded tabs for each ontology, containing the relevant concepts, relations (hierarchical only) and units.
The preliminary editor code can be found in the kde-cloudstorage git directory. It is certainly a low-priority project but a nice addition, especially considering the planned ability to submit service descriptions directly to a registry or marketplace through which service consumers can then select the most suitable offer. Know the service - with WSMO4IoS :)
How can desktop users assume command over their data in the cloud? This follow-up to the previous blog entry on a proposed optimal cloud storage solution in KDE concentrates on the smaller integration pieces which need to be combined in the right way to achieve the full potential. Again, the cloud storage in use is assumed to be dispersed among several storage providers with the NubiSave controller as opposed to potentially unsafe single-provider setups. All sources are available from the kde-cloudstorage git directory until they may eventually find a more convenient location.

The cloud storage integration gives users a painless transfer of their data into the world of online file and blob stores. Whatever the users have paid for or received for free, shall be intelligently integrated this way. First of all, the storage location naturally integrates with the network folder view. One click brings the content entrusted to the cloud to the user's attention. Likewise, this icon is also available in the file open/save dialogues, fusing the local and remote file management paradigms.

Having a file stored either locally or in the cloud is often undesirable. Instead, a file should be available locally and in the cloud at the same time, with the same contents, through some magic synchronisation. In the screenshot below, the user (who is apparently a friend of Dolphin) clicks on a file or directory and wants it to be synchronised with the cloud in order to access it from other devices or to get instant backups after modifications. The alternative menu point would move the data completely but leave a symlink in the local filesystem so the data being in the cloud will not change the user's workflow except for perhaps sluggish file operations on cold caches.

What happens is that instead of copying right away, the synchronisation link is registered with a nifty command-line tool called syncme (interesting even for users who mostly refrain from integrated desktops). From that point on, a daemon running alongside this tool synchronises the file or directory on demand. The screenshot below shows the progress bar representing the incremental synchronisation. The rsync-kde tool is typically hidden behind the service menu as well.

The current KDE cloud storage integration architecture is shown in the diagram below. Please note that it is quite flexible and modular. Most of the tools can be left out and fallbacks will automatically be picked, naturally coupled with a degraded user experience. In the worst case, a one-time full copy of the selected files is performed without any visual notification of what is going on - not quite what you want, so for the best impression, install all tools together.

Naturally, quite a few ingredients are missing from this picture, but rest assured that they're being worked on. In particular, how can the user select, configure and assemble cloud storage providers with as few clicks and hassles as possible? This will be a topic for a follow-up post. A second interesting point is that ownCloud can currently be used as a backend storage provider to NubiSave, but could theoretically also serve as the entry point, e.g. by running on a router and offloading all storage to providers managed through one of its applications. This is another topic for a follow-up post...
What is the free desktop ecosystem's answer to both the growing potential and the growing threat from the cloudmania? Unfortunately, there is not much to it yet. My continuous motivation to change this can best be described by this excerpt from an abstract of a DS'11 submission:
The use of online services, social networks and cloud computing offerings has become increasingly ubiquitous in recent years, to the point where a lot of users entrust most of their private data to such services. Still, the free desktop architectures have not yet addressed the challenges arising from this trend. In particular, users are given little systematic control over the selection of service providers and use of services. We propose, from an applied research perspective, a non-conclusive but still inspiring set of desktop extension concepts and implemented extensions which allow for more user-centric service and cloud usage.
When these lines were written, we did already have the platform-level answers, but not yet the right tools to build a concrete architecture for everyday use. The situation has recently improved with results pointing into the right direction. This post describes such a tool for optimal cloud storage in particular (optimal compute clouds are still ahead of us).
Enter NubiSave, our award-winning optimal cloud storage controller.
It evaluates formal cloud resource descriptions with some SQL/XML schema behind them plus some ontology magic such as constraints and axioms,
together with user-defined optimality criteria (i.e. security vs. cost vs. speed).
Then, it uses these to create the optimal set of resources and spreads data entering through a FUSE-J folder among the resources, scheduling again
according to optimality criteria. Even if encryption is omitted or brute-forced, no single cloud provider gets access to the file contents. Furthermore, transmission and retention
quality is increased compared to legacy single-provider approaches. This puts the user into command and the provider into the backseat. Thanks to redundancy, insubordinate providers
can be dismissed by the click of a button :-)
 Going from proof-of-concept prototypes to usable applications requires some programming and maintenance effort. This is typically not directly on our agenda, but in selected cases we
choose this route for increasing the impact through brave adopters. The recently started PyQt GUI shown here gives a good impression on how desktop users will be able to
mix and match suitable resource service providers.
This tool will soon be combined with the allocation GUI which interestingly enough is also written in PyQt for real-time control of what is going
on between the desktop and the cloud.
Going from proof-of-concept prototypes to usable applications requires some programming and maintenance effort. This is typically not directly on our agenda, but in selected cases we
choose this route for increasing the impact through brave adopters. The recently started PyQt GUI shown here gives a good impression on how desktop users will be able to
mix and match suitable resource service providers.
This tool will soon be combined with the allocation GUI which interestingly enough is also written in PyQt for real-time control of what is going
on between the desktop and the cloud.
Of course, there are still plenty of open issues, especially concerning automation for the masses - how many GB of free storage can we get today? Without effort to set it up? But the potential of this solution over deprecated single vendor relationships is pretty clear. If people want RAIDs for local storage, why don't they go for RAICs and RAOCs (Redundant Arrays of Optimal Cloud storage) already? In fact, a fairly large company has shown significant interest in this work, and clearly we hope on more companies securing their souvereignty in the cloud through technologies such as ours. And we hope on desktops offering dead simple tools to administer all of this, and complementary efforts such as ownCloud to add fancy web-based sharing capabilities.
Making optimal use of externally provided resources in the cloud is a good first step (and a necessity to preserve leeway in the cloud age), but being able to collaboratively participate in community/volunteer cloud resource provisioning is the logical path going beyond just the consumption. We are working on a community-driven cloud resource spotmarket for interconnected personal clouds and on a sharing tool to realise this vision. The market could offer GHNS feeds for integration into the Internet of Services desktop. I'm glad to announce that in addition to German Ministry of Economics and EU funding, for the entire year of 2012 we were able to acquire funds from the Brazilian National Council for Scientific and Technological Development (CNPq). This means that next year I will migrate between hemispheres a couple times to work with a team of talented people on scalable cloud resource delivery to YOUR desktop. Hopefully, more people from the community are interested to join our efforts, especially for desktop and distribution integration!

We're proud to announce the latest revision of SPACEflight, the live demonstrator for the Internet of Services and Cloud Computing. The overall scope of the demonstrator can be seen from the picture below. We consider SPACEflight to be a platform for exploring and showcasing future emerging technologies. At its core, the SPACE service platform handles management and execution of heterogeneous services as a foundation for marketplaces. Services can be deployed, discovered, configured and contract-protected, delivered to clients with frontends, rated, executed with access control, monitored and adapted. SPACEflight integrates this platform into a self-running operating system with a pre-configured desktop environment, scenario workflows and scenario services.
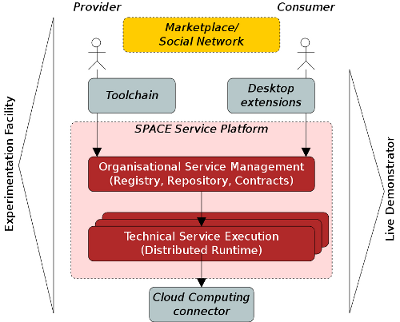
In version 1.0 beta6, a first light-weight engineering and provisioning toolchain was added (USDL service description & WSAG service level agreement template editors, service package bundler with one-click deployment button), thus extending the demonstrateable service lifecycle considerably. Read about the added functionality in our wiki.
Furthermore, the base system was stabilised and the service discovery was optimised for high query and synchronisation performance through new SOAP extensions.
You can download the image (for USB sticks and KVM virtualisation on x86_64 architectures, other choices will follow soon). Furthermore, a Debian package repository is available for installing the constituent platform services and tools individually on existing systems. Find out more information and download links on the 1.0 beta6 release info page.

This release certainly marks the most complete and high-quality integrated demonstrator of its kind. In total, more than 250 improvements have been applied over the previous version. The demonstrator has been presented in a conference presentation titled SPACEflight - A Versatile Live Demonstrator and Teaching System for Advances Service-Oriented Technologies at CriMiCo'11. Development is already continuing with the addition of more diverse service implementation technology containers.
The Dynvoker packaging metadata was about two years old. I've added the WADL4J package and updated all the others to version 0.3+20090814. Installing Dynvoker on a Debian-based system is now a matter of about five minutes again. The repo will be updated shortly with the new packages. A stable release (0.4) of Dynvoker will nevertheless take some more time.
The Dynvoker updates were motivated by the need to integrate it into a ТЕСЛА demo scenario. Unfortunately, even years after I've started using and reporting bugs against Mozilla XForms, it is still not available for Debian's Firefox variant called Iceweasel, nor is it free of bugs. In this case, SOAP4R doesn't like certain SOAP elements to be qualified, whereas Mozilla XForms doesn't like them to be unqualified. Dynvoker sits in between the service and the UI and cannot do anything about it.
The Access Gate is a generic proxy for web services. It handles streaming-enabled redirection, authentication and authorisation as well as monitoring. Some weeks ago an administration panel was created to display the contents of its redirection mapping database. Usually, service registration is performed automatically as part of the deployment process. However, for people who want to use the Access Gate as a standalone tool to protect legacy services, so far the only way to create mappings was to modify the database directly.
Today, the TinySec URL page was added. It allows users to just specify a locally accessible SOAP endpoint which turns it into a secure, globally accessible endpoint with WS-Security support. No more excuses for unprotected web services!

Rusco makes procedural web service development with Ruby as easy as writing a single class with a single method. It relieves the service developer of server-related overhead and is an important step into packagable, distributable, self-contained services.
The project was imported into Gitorious today. It uses the power SOAP4R and WEBrick and adds a convenience container around it, featuring inotify-based hot-deployment (and undeployment) of service modules, also called soaplets.
Rusco ships with some powerful samples such as the fortune telling service. It does nothing else but invoking fortune as an external process and delivering the bright-minded citations of the past to the service user. However, it demonstrates quite nicely the late binding and authentication options available with today's web service protocols. This makes Rusco an ideal tool not just for further hacking and research, but also for the upcoming computer science lectures beginning in autumn 2009.
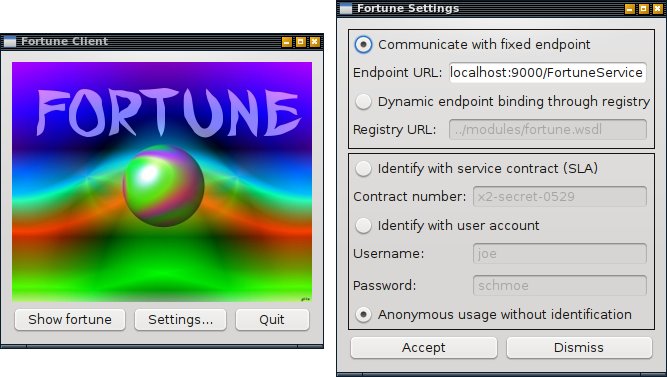
A Debian package with screen-wrapped daemon and all sorts of preconfigured paths and dependencies is also available, of course.
Woo-hoo, cloud computing.
(Thousands of teens start screaming.)
Enough already. What I found rather disenchanting was the lack of a tiny tool to enforce mandatory access control and usage monitoring. Furthermore, the few implementations available to mere mortals are rather technologically challenged, to put it mildly. This left me no chance but to come up with a concept of my own. The result is a PHP-based SOAP/REST proxy. Naturally, PHP doesn't make this tool fast or nice, but it allows for a quick drafting of a prototype. Eventually, an extension of das Schäfchen would seem natural since it can already be used as a reverse HTTP proxy with authentication.
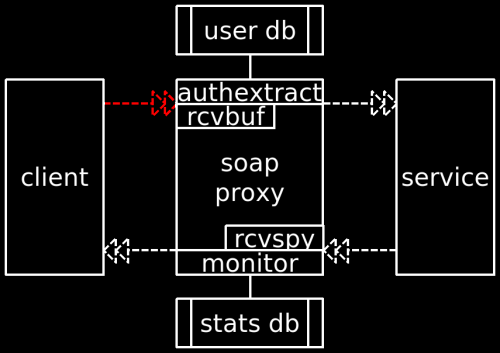
There are some interesting questions arising from any such concept. For example, the ability to accept streaming service calls is highly important to keep the duration of data presence on the proxy low by pushing it to the backend as soon as it arrives. However, no such pushing should happen until the user is authenticated, which happens with protocol-specific mechanisms, unless access for that particular service has been configured to accept anonymous users. Furthermore, in case one only trusts the proxy but not the services behind it, the proxy should strip authentication information, i.e. modify the stream during its redirection. This requirement is fundamentally incompatible with the SAX API and eventually will lead to another parser model. In the meantime, however, an alternative non-streaming mode is available as well. Further insufficiencies can be found in the way PHP interacts with Apache. There is no simple way to retrieve all the original headers. Therefore, the tools contains some workarounds until it can run in standalone mode.
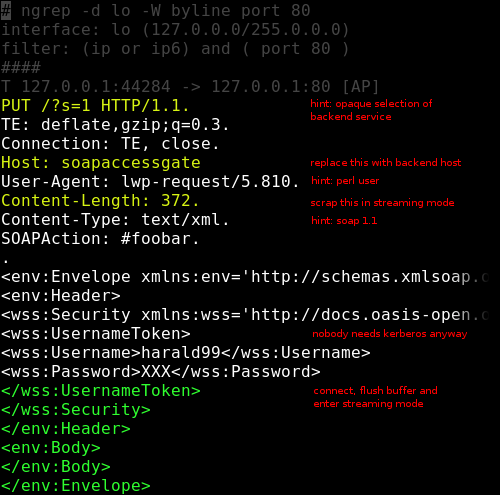
After some hacking, it has turned out to work fairly well at around ~500 lines of code. The first release is scheduled for the end of the month.
Heutzutage muss alles als Dienst verkauft werden. Software-as-a-Service, Monitoring-as-a-Service, Platform-as-a-Service, ja geradezu Everything-as-a-Service.
Für den ad-hoc-Zugriff auf Dienste kann man bekanntlich den Dynvoker verwenden, welcher einen generischen Client darstellt. Da Dynvoker zwischen den Anwendungen des Benutzers, wie beispielsweise einem Webbrowser, und den zu nutzenden Diensten steht, kann er auch selbst als Dienst angesehen werden. Abgeleitet von den Formaten der gesendeten Formulare definiert er eine Basismenge an Schnittstellen nach außen. Bisher sind dies eine Variante von XML-RPC, dem Übertragungsformat von XForms und Web Forms 2.0, sowie application/x-www-form-urlencoded für Web Forms 2.0 und Web Forms 1.0 alias den guten alten HTML-Formularen. Zu dieser Basismenge könnte sich noch SOAP gesellen, um einerseits die Anwendung direkt in eine SOA integrieren zu können, und andererseits eine weitere Formatalternative von XForms zu unterstützen.
Interessanterweise ergibt sich hierbei dann eine Rekursion in dem Sinne, dass man mit dem Dynvoker dann auf den Dynvoker zugreifen kann. Dabei bekommt man allerdings nur eine Liste von möglichen Operationen zu sehen, da die interne Prozesslogik fehlt. Hier sticht die Forschungsfrage heraus, inwieweit man diese Logik tatsächlich nach außen sichtbar machen kann, etwa über eine clientseitig ausgeführte, möglicherweise leichtgewichtige Prozesssprache (Variante eins), oder sich auf GUI-Generierung bei Bedarf seitens des Dienstes verlassen möchte, ähnlich wie das bei BPEL4People oder dem Ansatz von UPATMI der Fall ist. Wenn man diese Abarbeitungslogik erfassen kann, können auch autonom vom System UI-Optimierungen vorgenommen werden, etwa die Zusammenfassung von mehreren Schritten in einem UI-Fragment.
Nicht umsonst wird die Prozessintegration von GUI-Ansätzen für Dienste in unserem Architekturmodell als 5. Dimension bezeichnet, und bisher gibt es trotz vieler erfolgsversprechender Ansätze hierbei keinen wirklichen Durchbruch. Die duale Betrachtung des Dynvokers sowohl als GUI-Tool als auch als ordinärer aber vielseitiger Dienst könnte die Forschung in diesem Bereich beschleunigen.